By Tony Lee
When setting up an Elasticsearch Logstash Kibana (ELK) stack, you may discover the need to test your Logstash filters. There are probably many ways to accomplish this task, but we will cover some techniques and potential pitfalls in this article.
Note: This article can be used to simulate any syslog replay for manual data ingest testing, but our example specifically covers Logstash as the receiver and a fabricated, but realistic, event.
Real-time Visibility
The first thing that will aid us in this ingest testing is real-time feedback. This could come from at least two potential places:
1) "Real-time" discovery search within the Kibana UI
This is accomplished by using the discovery dashboard, setting a search term you know to be in your test message, and a short refresh rate as shown in the screenshot below.
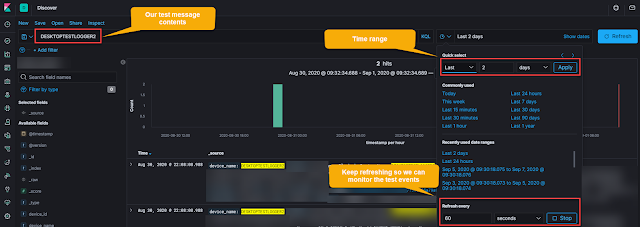 |
Figure 1: Kibana "Real-time" search using refresh interval
|
2) Monitoring the logstash log file for warnings or errors
For this, we will use the tail command with the follow option (-f) to watch it in real-time. The location of your Logstash log may differ so adjust the path as necessary.
tail -f /var/log/logstash/logstash-plain.log
We are looking for clues that may have prevented proper ingest such as:
[2020-08-31T20:25:21,997][WARN ][logstash.filters.mutate][main][b14e-snip-a422] Exception caught while applying mutate filter {:exception=>"Could not set field 'name' on object 'compute-this' to value 'see-this'.This is probably due to trying to set a field like [foo][bar] = someValuewhen [foo] is not either a map or a string"}
Encrypted or Unencrypted Listener
Once we have real-time visibility in place, we need to determine if the listening port is expecting encrypted data since this will determine how we replay traffic to it. There are a few ways to determine this:
1) Check the logstash filter config file
The example below, is an example of an encrypted port. We can see that is the case because we are defining the SSL information and have ssl_enable set to true.
input {
tcp {
port => 6514
ssl_enable => true
ssl_cert => "/etc/logstash/logstash.crt"
ssl_key => "/etc/logstash/logstash.key"
ssl_verify => false
}
}
2) Check the logstash logs for SSL errors
If you have an encrypted listener and you send data using an unencrypted transport method (such as telnet), you will see SSL errors such as the following:
[2020-09-01T13:46:20,758][ERROR][logstash.inputs.tcp][main][359d9-snip-c5038d] Error in Netty pipeline: io.netty.handler.codec.DecoderException: javax.net.ssl.SSLHandshakeException: error:100000f7:SSL routines:OPENSSL_internal:WRONG_VERSION_NUMBER
3) Use a tool (such as openssl) to verify the SSL connection
Below is an example of checking the SSL connection using openssl, but other tools can be used.
openssl s_client -connect <logstash_host>:6514
If the listener is expected encrypted data, you will see details such as certificate subject, issuer, cipher suites and more.
--snip--
subject=C = AU, ST = Some-State, O = Internet Widgits Pty Ltd
issuer=C = AU, ST = Some-State, O = Internet Widgits Pty Ltd
--snip--
SSL handshake has read 1392 bytes and written 437 bytes
Verification error: self signed certificate
--snip--
Methods of Replay
Now that we have real-time visibility and we know if the listener is expecting encrypted data or not, we can look at different techniques to replay the traffic. We will start with unencrypted methods first because we can later tunnel the unencrypted data to an encrypted listener. We will also examine replaying an entire packet (including the header) vs. replaying just the data and having the header added.
1) Unencrypted replay of an exact packet (Included specified time and no addition of a header)
If you have example logs that you can expect that include the date/time format, you can replay the exact message using netcat/ncat. Keep in mind that you are most likely sending a static time, so you will need set your Kibana time range appropriately.
First, place the contents of your event in a test file, we created a file called testevent.txt with the following contents (notice the included date and time):
<46>1 2020-08-31T02:08:08.988000Z sysloghost ExtraField - - [Location] Event Type: OurTest, Event Name: Blocked, Device Name: DESKTOPTESTLOGGER2, File Path: C:\Windows\system32\foo.ps1, Interpreter: Powershell, Interpreter Version: 10.0.18362.1 (WinBuild.160101.0800), User Name: SYSTEM, Device Id: 4eaf3350a984
Second, use netcat or ncat to send the data to your listening port. The example shown below is sending to an unencrypted listener (be sure to replace logstash_host with the IP or hostname of your logstash server):
ncat <logstash_host> 6514 < testevent.txt
Then just monitor the logstash log and real-time search in Kibana to see the event and/or potential errors.
2) Encrypted replay of an exact packet (Included specified time and no addition of a header)
For this we will use the same testevent.txt file from above and nearly the same command, but we will add --ssl to force ncat to perform the encrypted handshake.
ncat --ssl <logstash_host> 6514 < testevent.txt
3) Unencrypted replay of an exact packet contents with an updated time
If you have packet contents, but want the header updated with the current time, you might be able to use the logger command in Linux. The trick here is to get logger to reproduce your expected header. Use the following steps to attempt this:
Understand the logger options:
logger --help
Read in our test event and output to stderr for troubleshooting:
logger -s -f testevent.txt
Use logger options to alter the header (in our case, it was --rfc5424=notq) to match what we need and then create a new file with only the content and no header. Ex: testevent_noheader.txt
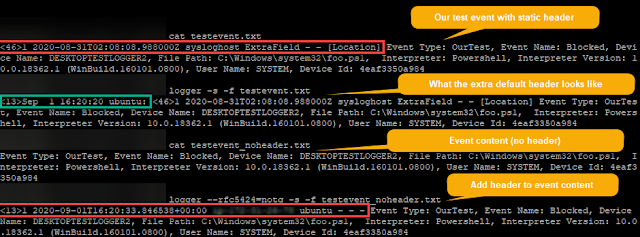 |
Figure 2: Reproducing the event with an updated header
|
Send the event to the unencrypted listener and check for it in Kibana and Logstash logs:
logger --rfc5424=notq -s -f testevent_noheader.txt --server <logstash_host> --tcp --port 6515
4) Encrypted replay of an exact packet contents with an updated time
Unfortunately our version of logger does not have an option to enable encryption. So, if you were able to get logger to reproduce the header + content in the step above, but need to send it to an encrypted listener, you could once again use ncat to assist. The following command creates an unencrypted listener on your local host on port 6515--then anything written to that local port will be sent on in an encrypted state to port 6514.
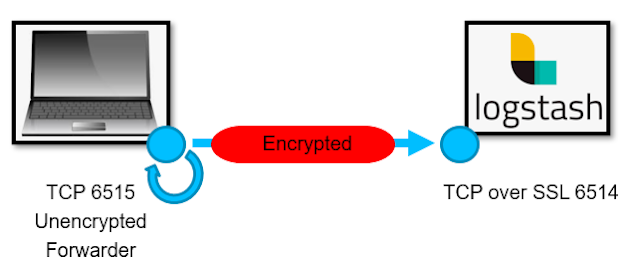 |
Figure 3: ncat listener to send data onto Logstash using SSL
|
Step 1) Create the listening wrapper:
ncat -l 6515 -c "ncat --ssl <logstash_host> 6514"
Step 2) Send the packet to the wrapper using logger:
logger --rfc5424=notq -s -f testevent_noheader.txt --server localhost --tcp --port 6515
Conclusion
We are just scratching the surface in ways to test data ingest components such as Logstash. For instance, this could be expanded to include scripting with variables that are replaced with random data to generate more robust values. But that will be an exercise left to the user (or maybe a future article). We do hope this article proved useful and would love to know what you use for testing data ingest. Feel free to leave comments in the section below. Thanks for reading.